p.s. Did you know we have a Slack community for UX localization? Join right here – and don't forget to join the relevant language-specific channels, too. Can't wait to see you there!



More to read
Great localization content in your inbox. Unsubscribe anytime.
Localization is massively complicated, and a lot can go wrong in the process. See how you can solve your biggest localization problems through some professional tools & tricks.
(Special thanks to Kinneret Yifrah for pushing me to write this post! This was originally posted in the Hebrew Microcopy Blog). Think writing UX copy is difficult? Try managing content for multiple languages at the same time. Localizing a product into a new language is a massively complex process, with dozens of moving parts. With so many people, cultures, and considerations involved, it's no wonder companies find it a struggle.
This issue is further complicated by the fact that the localization industry hasn't fully transitioned into a tech mindset yet. Practices and procedures product companies take for granted haven't seeped yet into localization agencies, creating a deep knowledge and communication gap.
I spent more and more time over the past years consulting companies on localization - from small startups to large international corporations. And so many of the product, marketing, and content managers I've met described feeling helpless or powerless when trying to take control over their localization workflows. With such fast international growth over the past couple of years - COVID-19 definitely had a hand there - teams often feel like localization efforts are spiraling out of their control.
The reason for this is that good workflows and practices take time to establish. You often need months - or even years - to create the background materials and process needed. Then there's the little issue of training your team and finding and retaining good linguists.
But I didn't write this to get you down: I wrote this to help you grow. Don't forget - this is 2022. Cars do their own driving. Drones bring us food. There's no reason why tech can't help us get better localization results, too. So as the title states, this piece will cover 5 localization pitfalls - and the technological solutions you can use to overcome them.
I'll be going over some of the key issues companies face when translating their incredible UX copy into other languages, and introduce you to some great software that can help. If you're working on localizing your app and need some more info on getting started, mark this post up for later, too: Getting started with app localization: A step-by-step guide.
But first - what are localization tools, anyway?
A couple of decades ago, people decided the old-timey way of doing translation is no longer effective enough. So they nixed Word documents and handwritten faxes (yes, that was a thing back in the day) for advanced tools meant to streamline translation. Obviously, those came a long way since - and these days we have tools to serve two goals:
Tools to improve translation and localization (usually called CAT tools = computer-aided translation tools)
Tools to manage translation and localization projects (usually called TMS tools = translation management systems)
Today, we'll focus on the first category - CAT tools. Plenty of translation management systems integrate with CAT tools and are able to automate a lot of the technical tasks involved - so if you're struggling with many projects, maybe a combination of the two is the right path for you.
CAT tools improve constantly, and they contain a multitude of features meant to help support translation and improve quality. At the end of this article, you can find a handy comparison chart with all major CAT tools available today. I've mostly focused on cloud solutions because life is too short for emailing files. Plus, in past years, cloud solutions have become the core of the industry. This means you can expect more innovative features and continuous updates using these vs. traditional system-installed software.
1. Keeping things in context
I know you know this, but it's so important, I'm just going to write it again. Context is crucial. Send your linguist context. Keep a pink neon PostIt with the word 'context' on your screen and underline it 3 times. Without context, you may as well give up now and invest your time in improving your spider solitaire score.
'Context' is essentially all information you need your international writers to know so they can make good choices. When they don't have that information, they often tend to fill the gaps on their own. It's because of what I like to call an ego bias, though I'm sure there's a more professional psychological name for it. Essentially, when not given certain information, we avoid asking multiple questions so as not to make ourselves look bad. Instead, we assume we're smart enough to guess the right answer ourselves. Spoiler alert: We're not, and we don't.
Context information could be things like:
The location of each string of text - for example, is it a title? Is it a CTA?
The audience these strings are meant for - who will be using your product and reading those texts? What are they looking to get out of it?
The voice of your product - How do you want your strings to sound? What emotions and sentiments are you trying to invoke?
The reasons for the choices you made - Why did you choose to write 'Book now' rather than 'Order now'? What were you trying to convey?
The goals you're trying to achieve - What are you trying you get your users to do? What do you want them to feel when they read your text?
I like to divide this into 'big context' and 'small context'. 'Big context' is things like voice, goals, and audience info - this is information that applies to the entire localization task - or even your entire product. Usually, you want your linguists to read that before they get started, and keep it in mind throughout the project.
'Small context' is string-specific - for example, the reasons why you chose a specific phrase; Or the location of the string in your design. Ideally, you want it displayed alongside each string so that linguists can keep it in mind while they work on it. Remember that the easier and more accessible you'll make it, the more you're likely to get your linguists to consider it as they work.
This is where tech comes in. Localization tools allow us to give our linguists that 'small context' they need in a way that's digestible and accessible - either by displaying notes next to the string, displaying screenshots for each string, or even letting linguists input their copy directly into the visual.

Check out this example of the visual context preview from Weglot. You can see your translation automatically populated. This allows for ultimate visual adaptation. No more awkwardly clipped lines, too-long button texts, or mistranslated paragraphs. Your linguists can better deal with placeholders and dynamic contennt - because they see in action how they'll be displayed. And they can make sure - in real-time- that their copy choices fit into the allocated space. The information's all there, right at their fingertips - and they can easily notice and fix issues as they go along.

The Phrase translation editor offers an in-context editor, and also allows you to attach screenshots and comments to every string. This information is displayed on the right side of the translation window, giving linguists full visibility of 'small context' information as they work.
2. Keeping terminology consistent
Your terminology is a huge part of how each user experiences your product. Sometimes, finding the right terms to use for different features and screens takes as much time as writing the rest of the product copy. That's because the right words can help users identify and connect with your product. They can make it more memorable or useable, keep confusion at bay, and greatly increase the value you're offering your users.
When writing UX copy for your product, you often maintain terminology consistency by referring to previously written copy; Using a design system with predefined components; Or referring back to a glossary file that your team keeps. But as you start delving into localization, you quickly learn it can be an enemy to consistency.
During localization projects, you have multiple people adapt each string. These people are not always familiar with your terminology - even if you do manage to keep your glossary list up-to-date. Plus, consistency is needed even for UI components you wouldn't necessarily refer to as 'terms'. If you're referring to a menu item, a button, even a section of your app, you want to make sure your linguist will choose the same term every time. Otherwise, things could get confusing for your users pretty fast.
This becomes more of a problem with complex systems and larger apps - where there are many, many tiny pieces of text. It also gets harder to maintain consistency when you're growing fast, adding multiple features over a short amount of time, or working with very large teams of linguists or through a large translation agency.
If you already have a localized product on your hands, it may be a good idea to take a few days and check the existing translations. If needed, you can ask your linguists to harmonize (= unify) your content before you move forward. This will also give you an idea of what terms and phrases need that extra attention in the future. Then, you can move forward with creating your CAT tool term list or glossary.
What is a glossary?
In its old-fashioned form, a glossary is a list of terms. Many companies already have a similar list stored in Excel or a shared Doc. A CAT tool glossary (sometimes called a termbase) is like that, but better. Once we set it up, our CAT tool recognizes glossary terms in our text, highlights them, and provides the linguist with the approved translation. This ensures our linguists have this crucial information right there when they need it (remember? If it's not accessible, it's not useful).
Once your linguists finish their translation, you can also ask the CAT tool to verify that terms were translated using the approved forms. If it recognizes an incorrectly translated term, it'll flag it and create a report you can share with your linguist. Of course, there will be false positives - the same words can be written in many forms, with your glossary only able to store one form per term. But this will be a great starting point for quality assurance, and a great way to make sure your linguists work within the instructions you defined.
Creating the glossary will be a bit of work, but it's worth it - saving a lot of time in the future and greatly boosting quality. To determine which words need to be included, you can make a list yourself or use a term extraction software. This is a piece of software that scans your source copy and retrieves terms based on frequency or other criteria defined in advance. Some CAT tools already have the option to retrieve terms, and others will require you to use external software (personally, I have had positive experience with Xbench).
The fallback - translation memory
What about cases where consistency is crucial, but there are no easy-to-define terms to put into your glossary? Often, you can't know in advance which terms you'll need to define. You still want your linguist to have a way to quickly browse past translations, figure out the best term themselves and try to maintain consistency as much as possible.
To do that, you keep a translation memory file. This is a smart file that stores inside all past translations for a certain langauge. Every time you start a project, you load it into the CAT tool to automatically 'absorb' your linguists' input. And every time a project ends, you save the most recent version of that file in your records. This way, your linguists (and you) always have the most up-to-date look into your product's translation history. It's a great record to learn from, and it's crucial if you want your linguists to be able to make informed decisions about the best direction to take.
Not only that, but CAT tools can automatically input matching translation memory entries. If a certain string was translated before (for example, if you have multiple CTAs with the word 'back to homepage' on them) - it'll populate it with the previous translation. This can save you some money - since you won't have to pay to translate those strings again and again. And of course, it'll help with consistency - as linguists won't even have to actively search to find the legacy translation. But be careful - sweeping changes can create context issues later on. If you do choose to populate translation memory entries automatically, ask your proofreader or reviewer to make sure they're still a good fit when considering the full context.
3. Covering huge workloads - fast
Okay, you say. All this is nice, but we're a modern business. We need an entire 500K-word app localized in 3 weeks (true story). Can't we just take a team of linguists and give each one a tiny piece of the content and have it all turn out perfectly? Pretty please?
Um, well. It's very common for companies to want to cover a lot of content quickly - deadlines are tight and C level is pushing and a launch is just around the corner. And there are tools that can help you achieve that with better (read: non-catastrophical) results. But before we go deeper into that, quick disclaimer: Good things take time. Good work takes time. If you decide localization is the right path for your product, you should give the process the respect it deserves. Otherwise, you may find yourself spending a whole lot more money and time later - fixing everything that went wrong when you rushed through things.
That being said, there are ways to help linguists collaborate in a more efficient manner, and speed things along in the process. Simply dividing a file into pieces won't do the trick - your linguists won't have access to each other's work. This means they won't be able to check the translation memory in real time. Instead, each will go in a separate direction - and you'll risk finding yourself with 6 different versions of the same CTA.
To do it better, you can use a CAT tool that allows several linguists to work on one file at the same time. This way, the translation memory is constantly synced for all linguists. They have read-only access to work their collegues do, and can even discuss among themselves to find the best solution for particularly cumbersome challanges.
Another helpful direction is to let your editor work on the file while the translator is still moving through it. This way, the editor can flag potential issues for the translator before they're even done working. They can update and improve as they go along - rather than repeat the same error over and over again. And of course, you'll be saving some precious time - since you're not waiting for your translator to cover the entire file.
For example, in systems that allow editing and translation of the same file at the same time, you can easily work on large files as well and make updates in terminology and wording at the beginning of the work, so you do not have to correct again and again later.
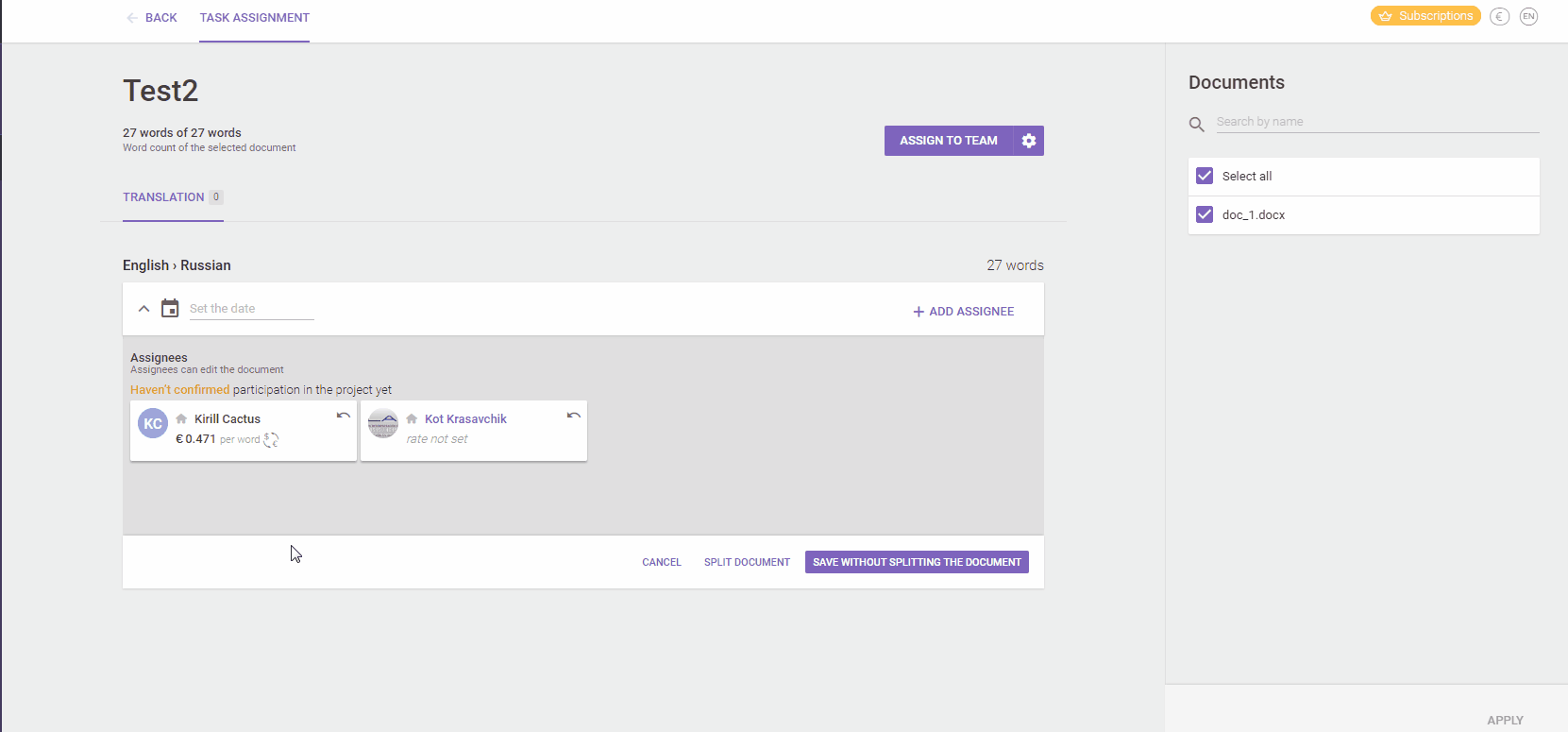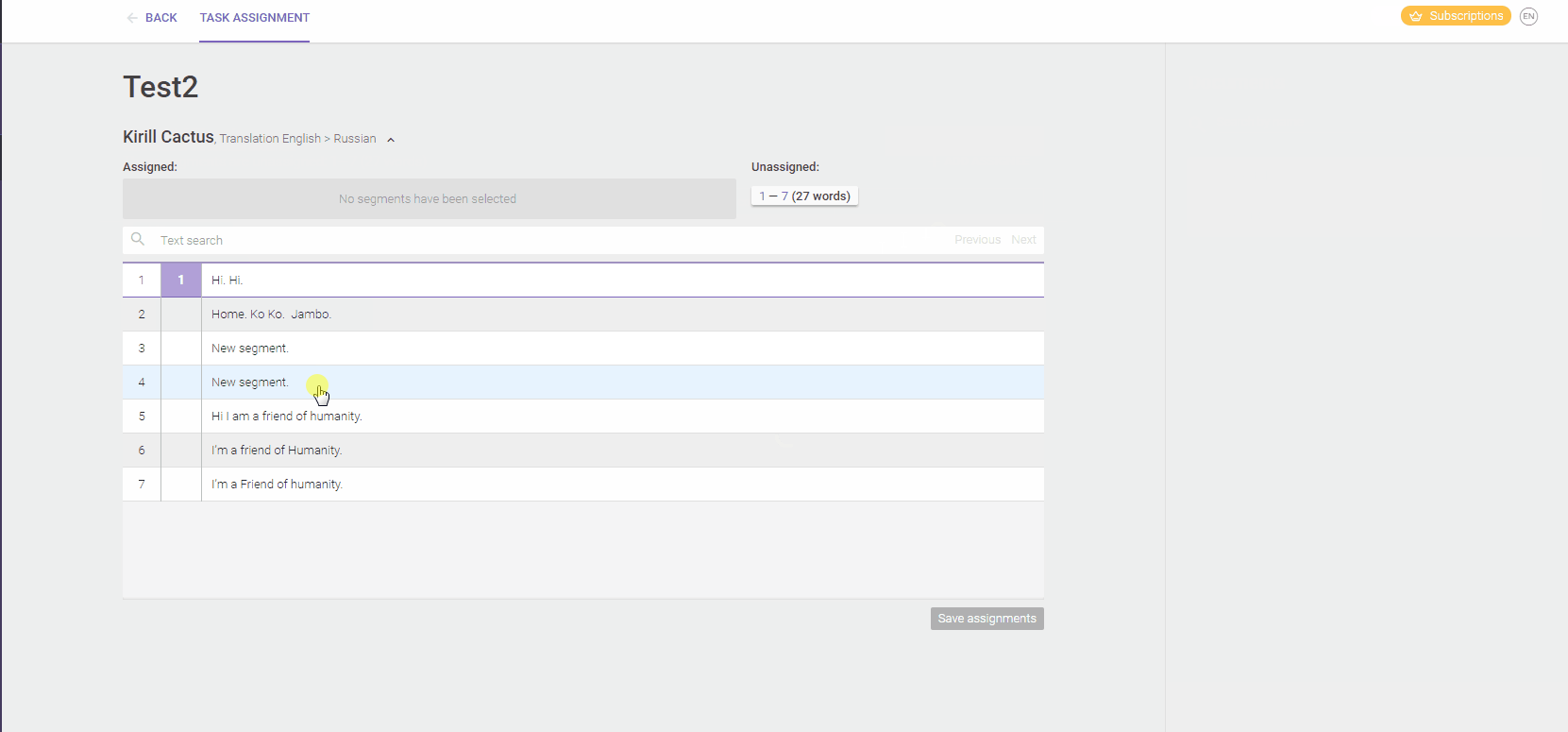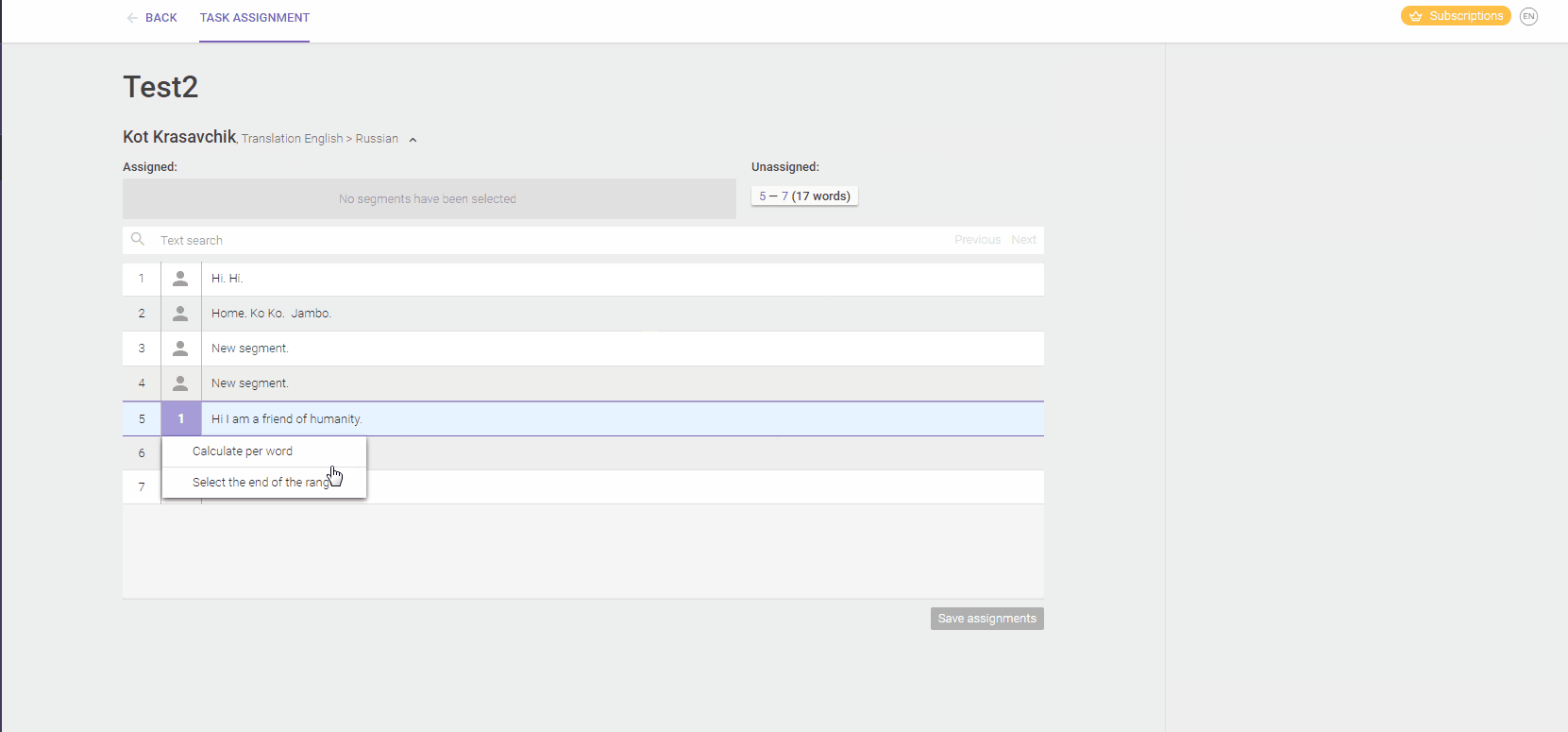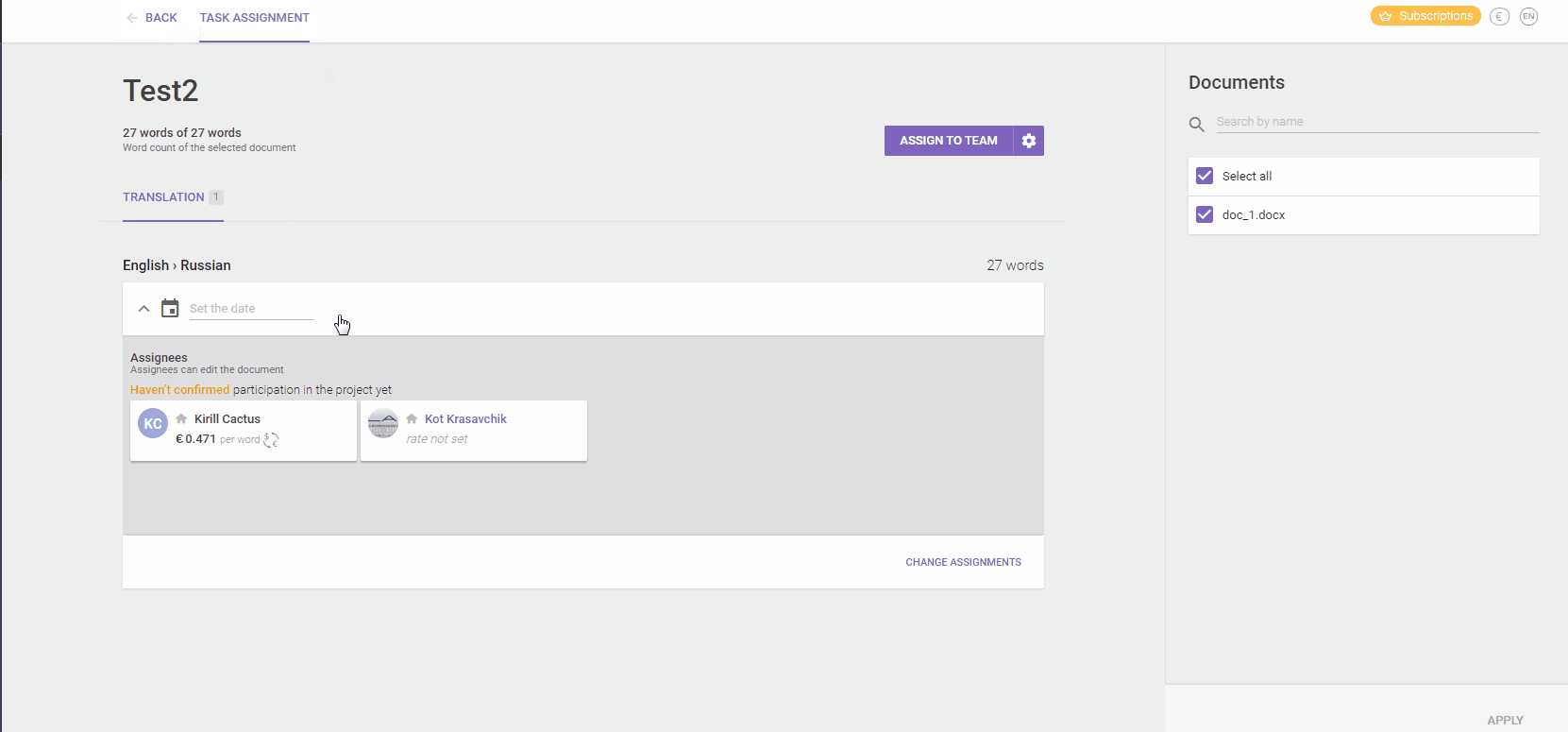
In Smartcat, for example, you can split a file between several linguists - assigning some of the strings to each of them. They'll all update the same translation memory and have read-only access to each other's work. They can also add comments to every string, to discuss issues and learn from each other. The project manager has eyes on their progress and can see exactly how many strings were translated by each linguist
.

The same thing happens in Matecat. You can have the tool split the file into as many as 50 parts, with all linguists having access to the full translation memory. This allows for faster turnaround times and more efficient work all-in-all.
4. Integrating with other tools
Now, let's talk about other stakeholders in our project. We want to make life easy for everyone, because good localization truly hinges on company-wide cooperation. Fortunately, all cloud tools today offer some level of stack integration - both to pull source text for translation into the software, and to push it back in after the work is done.
Integration like that is wonderful, and not just because it keeps everyone happy. When you don't have to load files by hand, you avoid a lot of the human error this process is traditionally riddled with. On top of that, keeping files current in a fast-moving, constantly-updated environment becomes much easier - as it's easy to know which file is the most recent one synced.
The best tool for your tech needs depends on your workflow and development stage. For example, if your product is still in design, you may need the CAT tool to sync with a design tool like Figma or Sketch, rather than a repository like GitHub or web development tool like WordPress.

Transifex, for example, integrates with a large variety of design, development, and eCommerce tools - from Figma to Bitbucket to Slack - thus ensuring you can focus on improving your localization results.

Crowdin also offers over 100 integrations, which means you can pull your content from repositories to UI tools, and push it back in with the click of a button once localization is done.

And Localazy promises to make any integration a breeze, by offering a 'set up and forget' automated solution for localization.
Generally speaking, If you're working with industry-standard tools you're obviously going to have an easier time - with the main CAT tools offering built-in integrations for agile deployment. But even if not, you can reach out to CAT tools providers and ask for their advice on the best way to integrate your stack.
On top of that, the features you choose to incorporate in your localization workflow will also impact your choice. Visual editors that sync with your will obviously require a tighter integration, pulling all visual and graphic components into the CAT tool, too. Text-only editors will be easier, but your team will probably need to hand-input all screenshots and context materials. Some tools offer better quality assurance, while others put their main focus on integration. So you will need to define your priorities before you make a final decision about the tool you choose.
5. Maintaining high-quality standards
Let's assume you just completed a 10K string project. Out of those 10K strings, 10% had double spaces. 12% had terminology inconsistencies. And another 3% had typos or spelling issues. You have one day to find every issue and fix it without inadvertently creating more damage.
Wait, step away from that ledge.
Some would stay quality control is the biggest challenge in localization. And it's easy to see why - with so many strings and components involved, staying on top of quality is a nearly impossible task. This is further complicated by the fact that linguists and product managers often don't have a shared baseline to compare things to. To put it simply, it's hard to define what 'good UX copy' even means. Not many translators have UX experience or knowledge, and not many product or localization managers speak the language currently localized. This makes discussing quality issues a very vague and ineffective experience.
Quality assurance tools can partially help with this task. They scan the translated strings and flag issues based on a predefined quality profile. The project or product manager can choose - from a list - what errors to flag, and what errors to refer to as critical. Obviously, you can only find rather technical, easy-to-define issues there - things like double spaces, strings exceeding the character count, typos, and incorrect punctuation. But even so, it's a big step towards ensuring your target content is well-written.

Here, Phrase) provides a detailed report of issues - missing numbers, terminology issues, spelling issues, and more. Linguists need to tap 'Run QA' to see these flagged. Once they do, they can resolve all issues in real-time. If an issue is set as critical, your linguist won't be able to deliver the file until it's resovled.

Lokalise provides project managers with a full QA overview, so they'll easily be able to have a clear view of the quality status of the project at all times. These problems are also flagged for linguists in real-time (no need to run a check), to ensure most of them are fixed early on.
The fact that these tools provide a standardized, detailed report of the issues found is an added advantage. It's a great start when discussing quality with your linguists, because you're able to talk about concrete issues rather than vague (though crucial) things like style and readability.
That being said, these reports should be taken with a grain of salt. On top of many, many false positives, they're not able to discover layout or alignment issues. They won't let you know if your linguist missed a piece of crucial context info. And they do take the focus off equally important topics like tone of voice and fluency.
In fact, since ensuring your linguists provide fluent content that adheres to the brand's voice is much harder (some would say: impossible), these issues are often neglected. Despite immense developments in computerized and automated translation in past years, maintaining fluency and brand consistency is still a mostly manual task. But who knows? With the massive strides taken in NLP in recent years, this may be something we'll be seeing very soon.
Wrapping it up
There isn't one perfect tool here - your needs will determine the right one for you. You go about this like you do with all good product processes: Begin with the problem(s) and move forward from there. To help you get started, use the comparison tables throughout the article to get a top view of the various tools available and their features. Good luck!
For more reading, check out 4 brands that impress with their localization strategies.
5 biggest UX translation problems - and how you can fix them in 2023
See how you can solve your biggest localization problems through some professional tools & tricks.
Michal Kessel Shitrit
|
02/01/23

